BERT-Large: Prune Once for DistilBERT Inference Performance
4.6 (336) In stock

Compress BERT-Large with pruning & quantization to create a version that maintains accuracy while beating baseline DistilBERT performance & compression metrics.

Large Language Models: DistilBERT — Smaller, Faster, Cheaper and Lighter, by Vyacheslav Efimov

Know what you don't need: Single-Shot Meta-Pruning for attention heads - ScienceDirect

Qtile and Qtile-Extras] Catppuccin - Arch / Ubuntu : r/unixporn

BERT compression (2)— Parameter Factorization & Parameter sharing & Pruning, by Wangzihan

PDF) The Optimal BERT Surgeon: Scalable and Accurate Second-Order Pruning for Large Language Models

Qtile and Qtile-Extras] Catppuccin - Arch / Ubuntu : r/unixporn

How to Compress Your BERT NLP Models For Very Efficient Inference
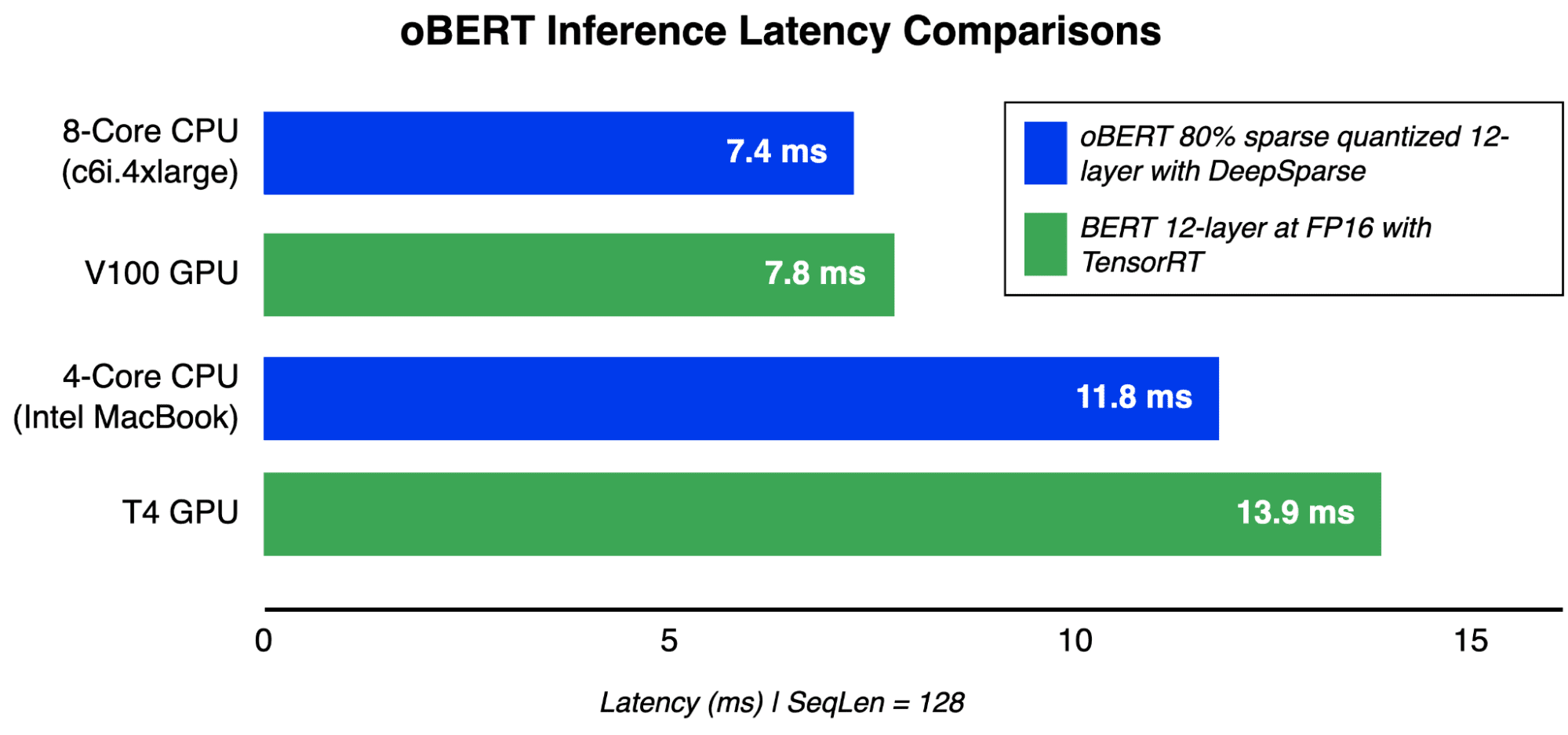
oBERT: Compound Sparsification Delivers Faster Accurate Models for NLP - KDnuggets
Delaunay Triangulation Mountainscapes : r/generative

How to Achieve a 9ms Inference Time for Transformer Models
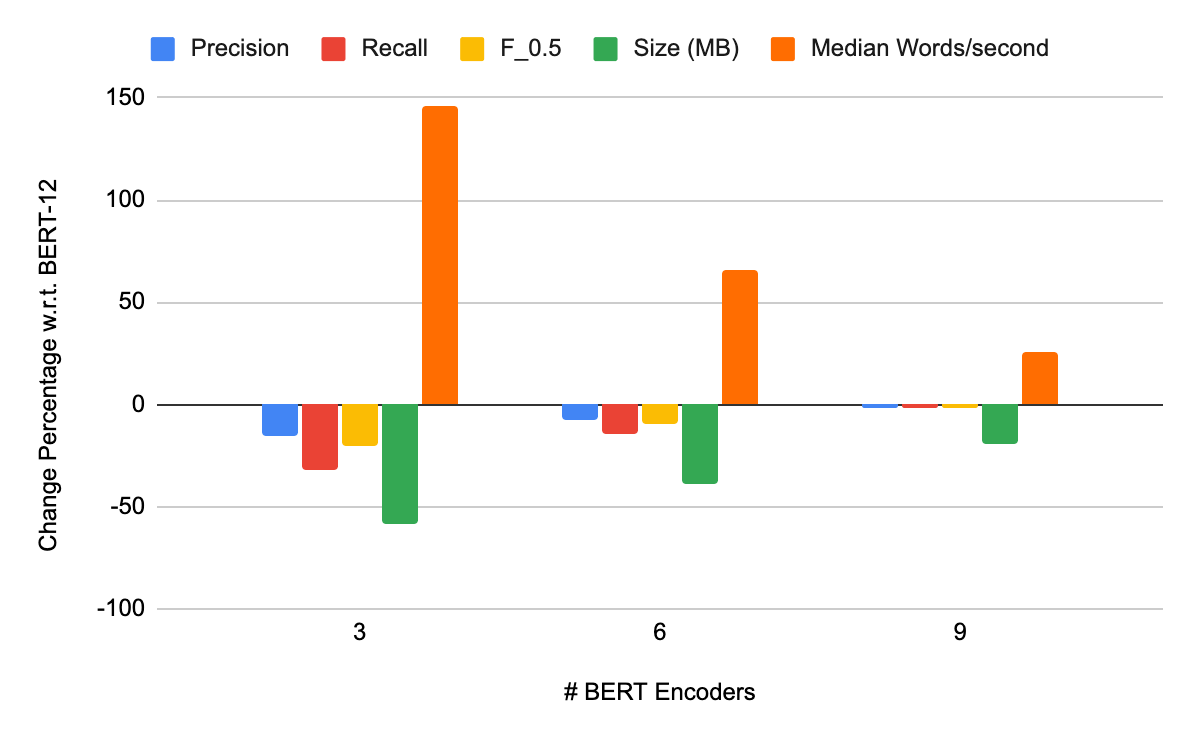
Distillation and Pruning for GEC Model Compression - Scribendi AI
Is a 2XL the same as a XXL? - Quora
PharmaSystems Weekly Pill Planner Box 1x per day (X-Large)
This ENVE MOG x Classified Bike Might Represent the Future of 1x – The Pro's Closet
Large Storage Box, Right Space Dubai
Hobby Horse French Tan 1X X Large Ultrasuede Chaps – Rock & Rail Western Wear
 Mary of Nazareth (TV Movie 2012) - IMDb
Mary of Nazareth (TV Movie 2012) - IMDb Bra Set Women Lace Transparent Half Cup Ultra Thin Plus Size Lingerie Underwear
Bra Set Women Lace Transparent Half Cup Ultra Thin Plus Size Lingerie Underwear Custom Seashell Wall Art Mosaic Unique Sea Shell Decor-beach Decor-coastal Wall Art: Eclectic Home Decor Home Inspirations
Custom Seashell Wall Art Mosaic Unique Sea Shell Decor-beach Decor-coastal Wall Art: Eclectic Home Decor Home Inspirations Under Armour Women's Tech V-Neck Twist Short-Sleeve T-Shirt
Under Armour Women's Tech V-Neck Twist Short-Sleeve T-Shirt Smartwool Seamless Strappy Bra - Women's - Clothing
Smartwool Seamless Strappy Bra - Women's - Clothing Wonderbra New Ultimate Plunge Bra A - F Cup from ASOS on 21 Buttons
Wonderbra New Ultimate Plunge Bra A - F Cup from ASOS on 21 Buttons