The LLM Triad: Tune, Prompt, Reward - Gradient Flow
4.6 (350) In stock

As language models become increasingly common, it becomes crucial to employ a broad set of strategies and tools in order to fully unlock their potential. Foremost among these strategies is prompt engineering, which involves the careful selection and arrangement of words within a prompt or query in order to guide the model towards producing theContinue reading "The LLM Triad: Tune, Prompt, Reward"
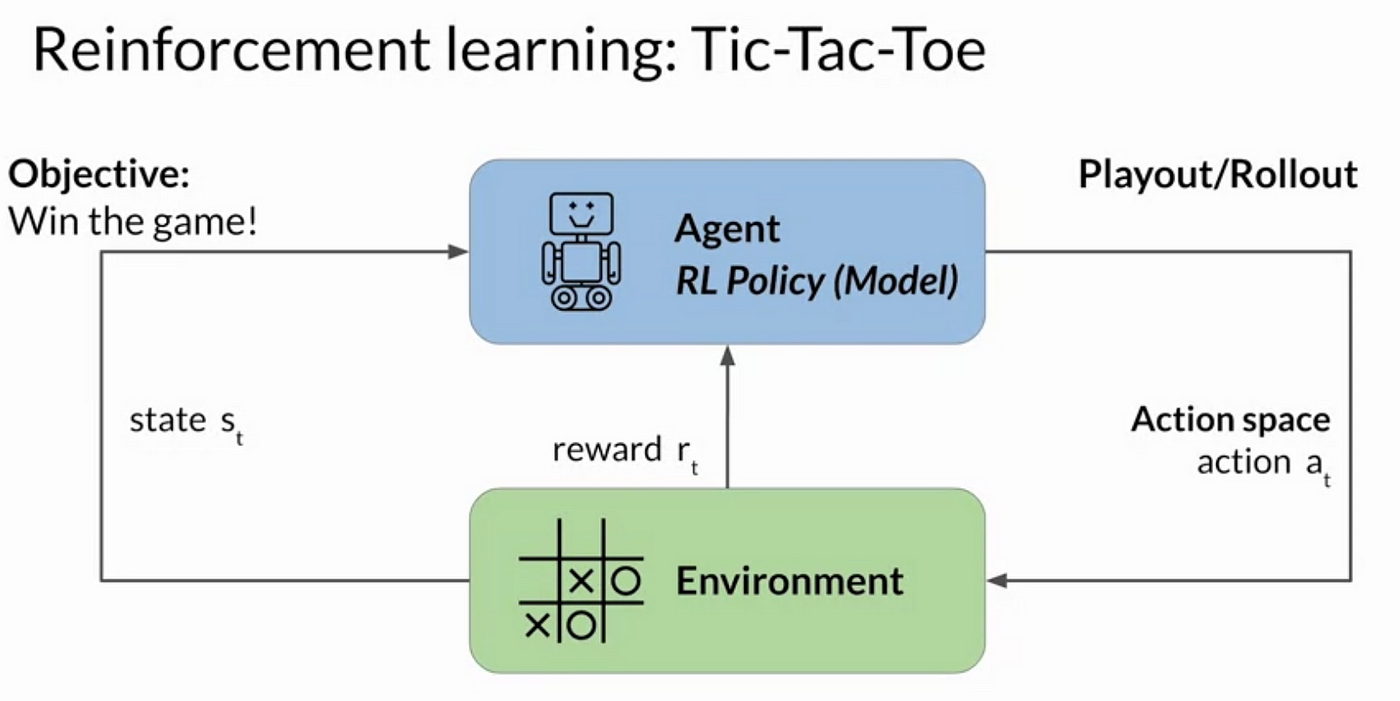
Reinforcement Learning from Human Feedback (RLHF), by kanika adik

Understanding RLHF for LLMs

Beyond Training Objectives: Interpreting Reward Model Divergence in Large Language Models

Some Core Principles of Large Language Model (LLM) Tuning, by Subrata Goswami
NeurIPS 2022
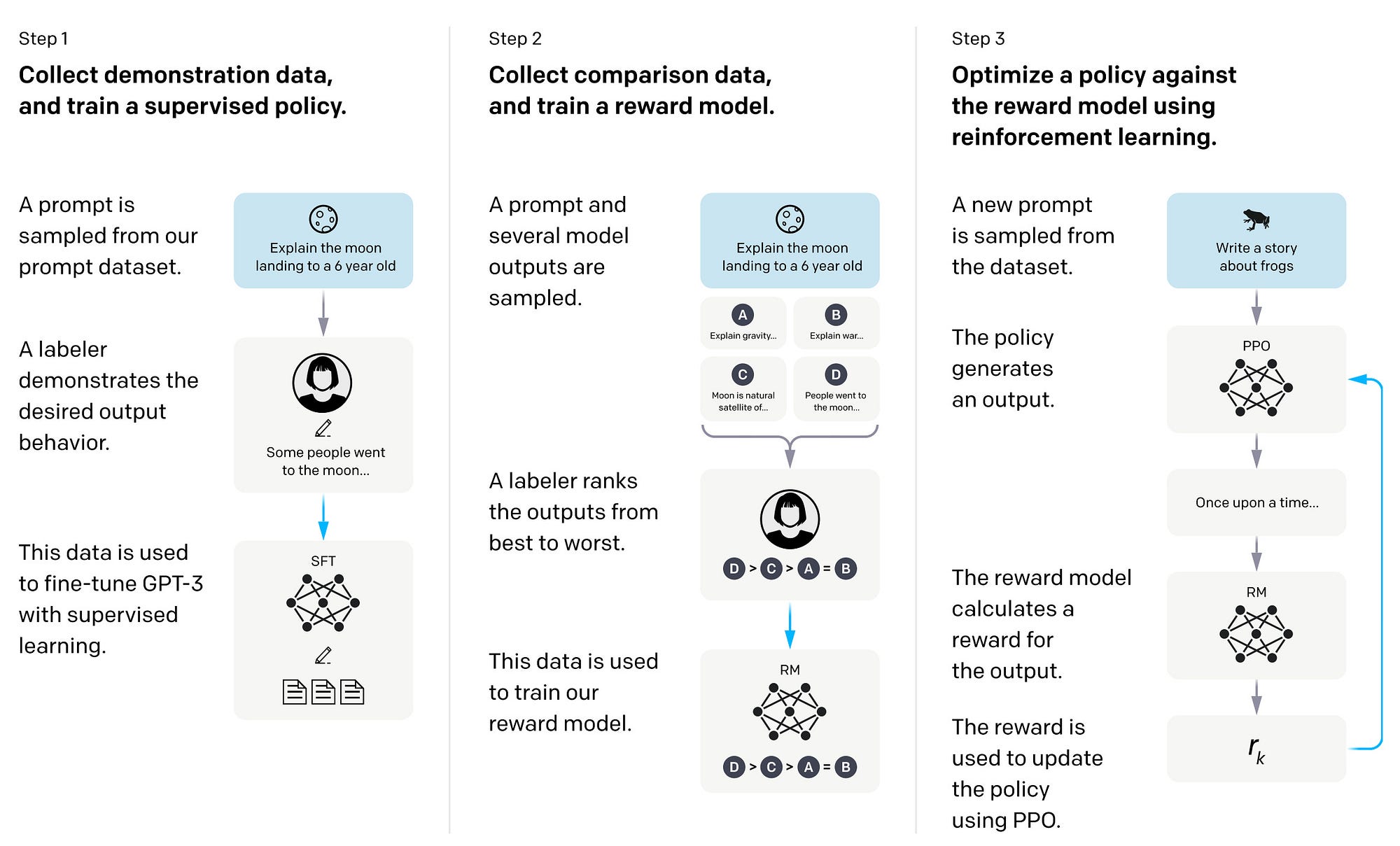
Train Instruct LLMs On Your GPU with DeepSpeed Chat — Step #1: Supervised Fine-tuning, by Benjamin Marie

Gradient Flow

How to Fine Tune LLM Using Gradient

A Comprehensive Guide to fine-tuning LLMs using RLHF (Part-1)
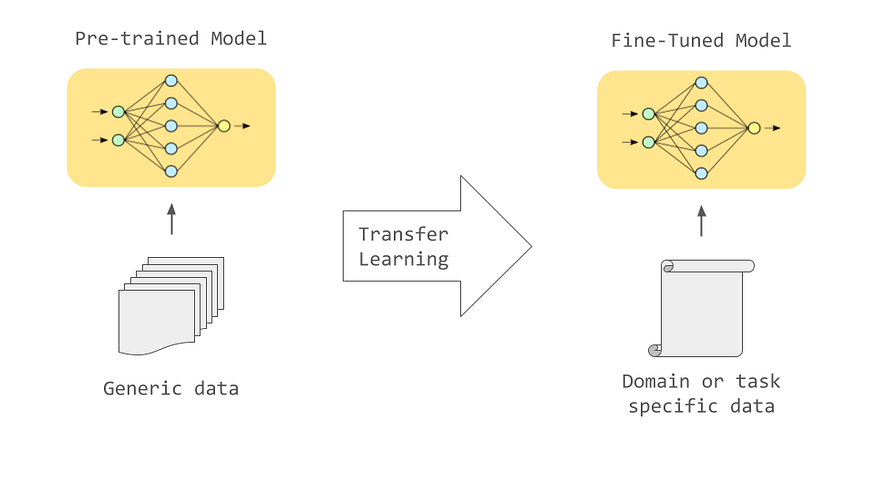
Fine Tuning LLMs for Code/Query Generation or Summarisation
Fine-Tuning Tutorial: Falcon-7b LLM To A General Purpose Chatbot
Fine tuning Meta's LLaMA 2 on Lambda GPU Cloud
How to Use Hugging Face AutoTrain to Fine-tune LLMs - KDnuggets
Fine Tune: Over 1,796 Royalty-Free Licensable Stock Vectors & Vector Art
Fine-Tuning LLaMA 2: A Step-by-Step Guide to Customizing the Large Language Model





